
Structured, Modular, Open: The DITA Promise, 20 Years Later
A chronological look at DITA's 20-year history — from early XML experiments to DITA 2.0's machine-interpretable knowledge model — told through the lens of one practitioner's career. In this presentation, I trace DITA's evolution from its 2003 origins to the release of DITA 2.0, showing how each version expanded the standard's power and purpose.
Originally presented at ConVEx 2026 in Pittsburgh. If you registered for ConVEx 2026, Comtech should have sent you (via the email address you registered with) access to the recordings on Friday, April 24th, 2026, in an email with the subject line, “ConVEx Pittsburgh Recordings.”
If you can’t find that email, contact ConVEx.
If you're newer to DITA and want a foundation before diving into its history, Introduction to DITA covers the architecture and its core concepts.
My essay in Women in Technical Communication traces one practitioner's path from technical writer to information architect in detail
TABLE OF CONTENTS
Introduction: The DITA Promise, 20 Years Later

I'm going to talk about DITA implementation from the point of view of a person who did not build DITA, but has been implementing it and working with it since before it was actually a standard. These are my milestones as an implementer — not a history of DITA releases, though in many cases those do map together. DITA was built on three foundational commitments: structured, so content is consistent and predictable; modular, so it can be written once and reused across contexts; and open, governed by a public standard rather than a proprietary vendor. Twenty years in, I find myself asking whether those commitments have been kept — and what they mean for what comes next.
About Amber Swope

Slide 2 - About Amber Swope
My name is Amber Swope. I've been doing this quite a while — over 20 years in information architecture and structured content. I hold a Master's degree in Professional and Technical Writing, and I co-authored the DITA Maturity Model with Michael Priestley. I've presented at conferences including STC and Best Practices, and in 2005 I gave one of the first DITA talks at a CIDM conference. My firm, DITA Strategies, Inc., focuses on helping teams understand how they can make the DITA standard work for them. Everything in this presentation comes from that work — consulting with organizations, helping them understand what DITA can do, and figuring out together how to make the investment pay off.
2003: Where Is Your XML?

Slide 3 - 2003: Where is your XML?
I was with Rational Software, and we were trying to single source content for two different development environments — one for IBM and one for Microsoft — out of HTML. That was a lot of HTML files and spreadsheets. When IBM acquired us in February 2003, the very first question we asked was, "Where is your XML?" They said, "Well, we've got this thing we're working on. Funny you should ask." We said, "Give it to us." The tool was rudimentary — a customized version of Arbortext called the IDW Workbench — and there weren't many templates. We did relationship tables in Notepad. But even so, it was so much better than what we had. Reuse in 2003 with HTML was nonexistent, and we really needed to get to a single source of truth. I was the information architect, and my counterpart on the technical side was Hadar Hawk. We implemented DITA, moved from HTML, and then helped other teams at IBM who were in the same pain.
2005: What Is DITA?

Slide 4 - 2005: What Is DITA?
When DITA 1.0 was released, I had a standard I could reference. Part of IBM's contribution of the standard to OASIS meant making sure people actually wanted it — a number of us were charged with going out and doing exactly that. In 2005, I gave six different DITA presentations at every content conference that year. Then, an IBM salesperson sold DITA support to a company in China without knowing that there wasn’t actually such a product, which is how Michael Priestley, Crystal Pomeroy, Seth Park, and I ended up in Shenzhen teaching DITA to Huawei. I showed up and their XML editor looked nothing like the one I used at IBM. I don't speak Chinese, I was teaching a standard that had just been released, and I was doing it in a tool I'd never seen before. It worked. And I realized I liked this — helping people discover how they could take the DITA toolkit and implement the parts of it that were meaningful to them. The core building blocks that came in with 1.0 — topics, maps, conrefs — were a game changer, especially conrefs. Coming from HTML with no reuse, having conrefs was a huge improvement.
2007: How Do You Implement DITA?

Slide 5 - 2007: How Do You Implement DITA?
By this point, people had their heads around what DITA was. The question shifted to how you implement it — and the answer really depends on your role. As an information architect, my job is to harmonize requirements from content strategists, publishing pipelines, delivery architects, and localization teams into the simplest, most usable set of elements that gives us the semantic richness we need, consistently and efficiently.
DITA 1.1 addressed real gaps starting with the limited filtering support in DITA 1.0. For enterprise organizations supporting multiple business units the extensible filtering was a necessary improvement. Bookmap gave teams doing book output a starting point and a set of publishing-specific metadata to work from. Because I love metadata, I was thrilled with the inclusion of the <data> element. Without it, it was hard to get the metadata we needed into the content at the places we needed it. As an architect charged with making content perform, that metadata support was a significant addition.
2008: What Should You Invest In?

Slide 6 - 2008: What Should You Invest In?
I left IBM in 2008 and joined JustSystems as a consultant. One of the things we realized was that now that people understood what DITA was and wanted to know what to do with it, we needed a framework for that conversation. So Michael Priestley and I co-authored the DITA Maturity Model. It maps six levels of maturity against both investment type and expected return: Topics, Scalable Reuse, Specialization and Customization, Automation and Integration, Semantics On-Demand, and the Universal Semantic Ecosystem. Michael and I have talked about refreshing it, and when we looked at it we said, "What would we really change?" We might update some wording and add AI somewhere, but the investment levels haven't changed. If you want scalable reuse, you have to get into topics first. If you want semantics on demand — and that's exactly what AI gives you — you don't get to skip the levels below it. I still use this graphic with every client I work with, because the investment hasn't changed: you want this, you need to invest in that.
For a closer look at how the maturity model maps investment to return, The Information Architect's Role in a Successful DITA Implementation walks through the DMM in detail.
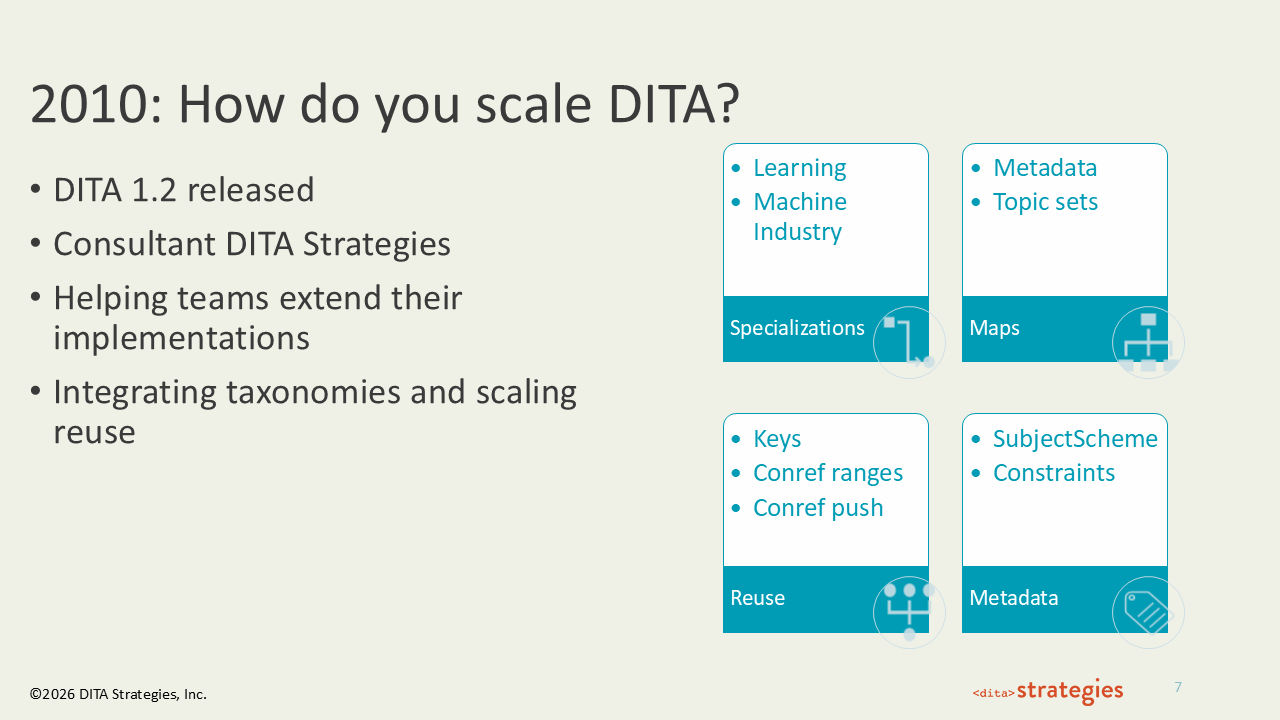
2010: How Do You Scale DITA?
Slide 7 - 2010: How Do You Scale DITA?
This was a huge DITA release in terms of new support. The addition of the machine industry and learning domains opened DITA up to a lot of organizations that had looked at it and said, "That's just too software-centric for us." Getting metadata into maps was also a long time coming — we had been working around it by putting a topic at the top just to carry the metadata and then hiding it. Keys were the first iteration of indirect referencing in DITA, and they were a significant addition. Before, the only way to do that was to set up a conref and put conditions on it — very complex if you wanted to do this at scale. And subject scheme was a game changer for integrating metadata into your DITA implementation. Having subject scheme means you can integrate your controlled vocabulary directly into your content rather than managing it separately through spreadsheets and publishing pipelines. It was at this point that I had gotten laid off from JustSystems — that was 2008 — and started DITA Strategies. There were no jobs, so I hung up my shingle, and I kept doing what I love to do.
2012: What About That Bird?

Slide 8 - 2012: What About That Bird?
I got to choose what I thought was momentous for this presentation, and I chose the bird. It took two years for IBM to let OASIS have it, but the DITA finch logo was donated to OASIS in 2012. Thank you, Michael Priestley. It's cute, and it's mine to include.
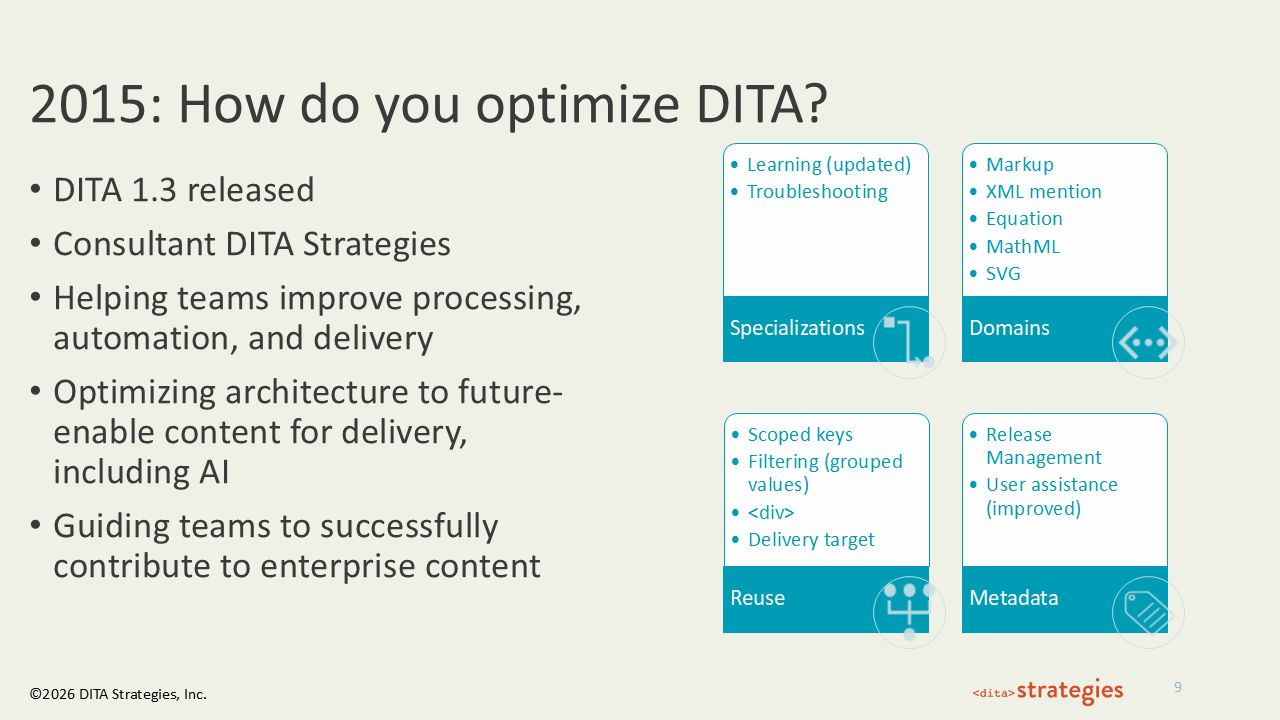
2015: How Do You Optimize DITA?
Slide 9 - 2015: How Do You Optimize DITA?
DITA 1.3, released in 2015, was the most technically ambitious version of the 1.x series. Specializations were updated to include revised Learning content and a new Troubleshooting topic type. This release supported new domains— Markup, XML mention, Equation, MathML, SVG — giving technical writers in engineering and scientific fields robust native support for the complex content types they were already trying to force into earlier versions. Reuse became more precise with scoped keys, grouped filter values, the div element, and delivery target attributes. Metadata gained release management support and improved user assistance features. This period focused on improving processing pipelines, automating publishing, and designing architectures capable of delivering content to emerging channels. I was using the phrase "future-enable content for AI delivery" with clients at this point. Structured content wasn't just a publishing strategy anymore — it was becoming an infrastructure decision.
2026: What Is Next for DITA 2.0?

Slide 10 - 2026: What Is Next for DITA 2.0?
DITA 2.0 is a deliberate reset. Rather than adding incrementally to the 1.x architecture, it returns to fundamentals — removing deprecated elements, tightening the specification, and establishing a cleaner baseline for the next generation of implementation. The six key changes I highlight here tell that story: simplified (a reduced, more coherent element set), media support (native handling of multimedia content types), nested steps (improved content reuse), enhanced troubleshooting (a more robust specialization for diagnostic content), improved bookmap (cleaner structure for long-form document assembly), and extended key support (greater flexibility in how content is referenced and reused). DITA 2.0 provides machine-interpretable knowledge to power AI systems. Structured, semantically labeled content is no longer valuable only for human readers and publishing pipelines. It is now the kind of content that AI retrieval and generation systems can actually use. That's not an accident of timing — it's the promise of structured content finally meeting the moment it was built for.
Let's Connect

Slide 11 - Let's Connect
If any of this resonates — whether you're navigating a first DITA implementation, trying to scale an existing one, or thinking about how to position your content architecture for AI — I'd love to talk. You can connect with me on LinkedIn or schedule a discovery call to chat. Twenty years in, I'm more convinced than ever that the investment in structured content pays off. The organizations that made that bet early are the ones best positioned for what's currently happening in tech and what's coming next.