
LavaCon 2024 — Navigating AI: Real Tales from Content Frontiers

Amber Swope, Lief Erickson, and Joe Gregory-DeBernardi gave this presentation at LavaCon 2024 in Portland, OR. This study was done in 2023 and 2024, and as such, is limited by the technology of that era.
TABLE OF CONTENTS
Who We Are and Why We Did This

This case study was a collaboration between three people from three different companies: Joe Gregory-DeBernardi, a taxonomist and information architect specializing in metadata frameworks and enterprise content platforms; Lief Erickson, a content strategist and co-founder of Intuitive Stack with deep roots in information architecture and technical communication; and me, Amber Swope, information architect and owner of DITA Strategies. None of us were commissioned by an organization to do this. We started it out of curiosity — we wanted to understand generative AI from the inside, not just read about it. That independence shaped what we chose to test and how honestly we could report what we found.
The Room Was Working on AI — But Not From a Content Perspective

At the start of the session, we asked the room how many people were currently involved in an AI project. About half the hands went up. Then we asked how many were participating as a subject matter expert, an information architect, or a content professional. The hands dropped significantly with each question. That gap is the problem we were trying to address. A lot of people are on AI projects right now, but very few are coming at it from a content perspective — and that matters more than most organizations realize. We built this case study specifically to make the case for why content professionals need to be at the table.
What Shaped Our Results

Four things had the most measurable impact on what the AI system returned: question ambiguity, archetypes, engineered prompts, and knowledge facts. These are not abstractions — each one was a variable we deliberately manipulated across testing conditions. We found that unclear or broad questions produced inconsistent outputs regardless of how well the system was configured. Archetypes — simplified descriptions of the user type receiving the response — shifted how the system framed its answers. Engineered prompts, where we structured the question with explicit variables and context, consistently improved response quality. And injecting specific knowledge facts into the prompt produced a measurable score improvement. None of this is surprising in retrospect, but you have to run the tests to know which levers actually move the needle.
Why Content Professionals Belong on AI Projects

Content professionals bring something to an AI project that most technical teams do not have on their own: they know the content set, they understand how it is structured, they know the audience, and they work with metadata. But beyond those functional competencies, there is something less tangible that turned out to matter a lot in our work — curiosity. Content professionals are trained to ask why, to push back on the first answer, to follow a thread until it makes sense. That disposition is exactly what effective AI evaluation requires. If you value accuracy and truth, you cannot accept what the system returns at face value. You want to understand how it got there, where it sourced that information, and whether it would hold up under scrutiny. That questioning mindset is what improves an LLM over time.
The Roles We Had on Our Team

Our project involved seven distinct roles: technical lead, ontologist/taxonomist, subject matter expert, content professional, project manager, prompt engineer, and business champion. Not all of these need to be separate people, and in a smaller organization many of them will overlap. But it is worth thinking through each role deliberately rather than assuming the technical team will cover what it cannot actually cover. The business champion role is one people often underestimate. In any organization doing this work, someone with authority needs to be actively sponsoring the effort — not just approving the budget, but insisting clearly that the decision makers are including content professionals in the process and using their input to shape the outcome.
Our Timeline: What It Was Like Then vs. Now

We started this project about a year and a half before presenting it at LavaCon 2024. When we began, we were naive — confident that between us we had enough content and technology knowledge to make meaningful progress, but underestimating how fast the landscape was changing beneath our feet. There was very little practical guidance available at the time. We were figuring things out as the technology itself was shifting. The contrast with where things stand now is significant. There is substantially more structured knowledge, more shared experience, and more community discussion to draw from than existed when we started. If you are beginning an AI project today, you are starting in a much better position than we were — but only if you actually use those resources rather than assuming the technology will do the heavy lifting.
How We Structured the Work

Our process followed a standard research arc: prepare, develop, test, analyze. The preparation phase took longer than expected. Because we were not building a product for a client, we had to define our own scope — what to test, what questions to use, what content to prime the system with. That kind of scoping work is harder without an external forcing function. Developing the prompts required deliberate decisions about what kinds of questions to ask and what we were actually trying to learn from the responses. Testing happened in multiple rounds. Analysis is still ongoing. One thing the timeline made clear is that doing this well requires sustained investment — not a sprint. We were not working on this full time, and the pace reflected that.
What We Put Into the System

We ran the system in an Azure environment and used three primary source documents as training content: the DITA-OT documentation, Eliot Kimber's DITA for Practitioners, and Leigh White's DITA for Print. We want to acknowledge XML Press, Eliot Kimber, and Leigh White for making their materials accessible to us. The question set came from actual search queries submitted to the DITA-OT website — real user questions rather than ones we invented. We built two archetypes to represent the types of people who would realistically come to that site: a transform developer and a technical writer with no formal coding background. Those archetypes, along with the source content, the engineered prompts, and injected knowledge facts, made up the core components of each testing condition.
Testing Whether Archetypes Changed Responses

The core question on archetype testing was simple: would the system adjust its language and framing meaningfully based on who it was told was reading the response? We used two archetypes — a content author, representing a technical writer who might have limited coding background, and a DITA-OT developer, representing someone with software development experience and technical fluency. We fed the archetype descriptions directly into the engineered prompts. We did see meaningful differences in how the system responded to the same question depending on which archetype was active. The response shifted in assumed technical depth. This is a practical signal: if you can identify who is asking a question — and in a logged-in product environment you often can — you can use that information to shape the prompt and improve the relevance of what comes back.
How We Decided What "Good" Looked Like

Establishing assessment criteria was harder than we expected. We focused on two things: truthiness — meaning whether the information was accurate and not hallucinated — and conciseness. We used a simple one-to-three scale, with our subject matter expert doing the evaluation. We also asked AI systems what criteria they would use to evaluate themselves, which produced results that largely overlapped with our list but were not identical. What became clear quickly is that accuracy alone is not sufficient. A response can be technically correct and still not be useful — for example, answering which DITA-OT version supports a specific feature by naming one version when the correct answer involves four. That kind of partial truth can mislead users. Defining what counts as a good answer requires much more deliberate thinking than most teams anticipate going in.
The Semantic Maturity Model: Why Your Content Layer Matters
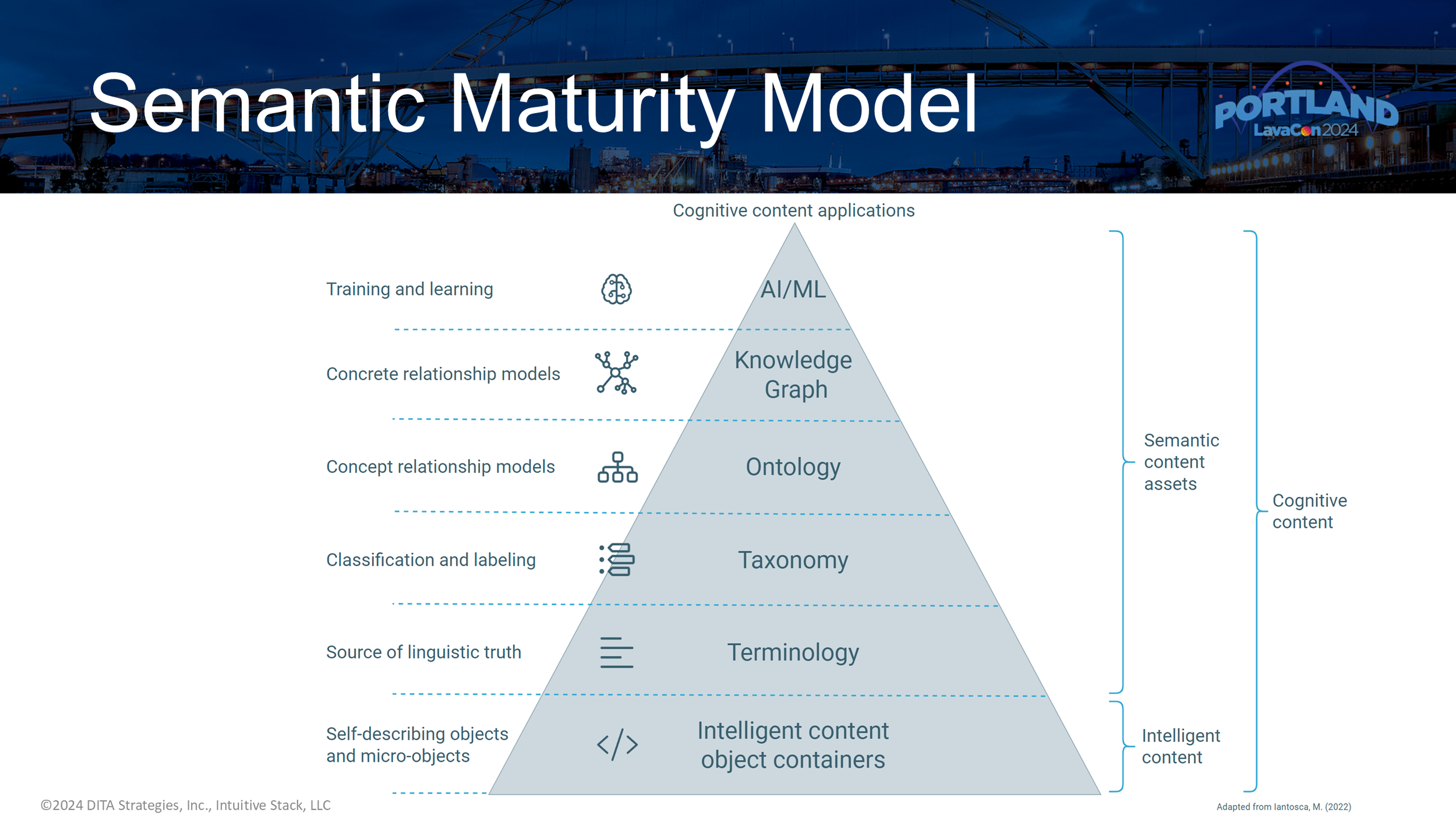
We referenced Michael Iantosca's Semantic Maturity Model as a framework for thinking about where AI-ready content comes from. The model starts at the bottom with structured content — and that foundational layer matters more than most AI discussions acknowledge. If you are feeding a generative AI system a collection of PDFs, you are starting with very little semantic information. XML-based content, properly structured, gives the system much more to work with. Moving up the model, you have terminology, taxonomy, ontology, and knowledge graphs — each layer adding more structured context that allows the system to retrieve, classify, and reason more reliably. Joe walked through how taxonomy supports classification and metadata, how ontology describes entity relationships in a domain, and how knowledge graphs bring that structure to life in ways that directly support retrieval-augmented generation. This is the infrastructure that makes intelligent content behave intelligently.
What Happened When We Injected Knowledge Facts

We ran the same prompts twice — once without injecting knowledge facts into the prompt, and once with specific knowledge facts included alongside the question. The baseline score was 2.15 on our one-to-three scale. With knowledge facts injected, the score moved to 2.4. On a three-point scale, that shift is statistically meaningful — the distribution narrows and the improvement is consistent rather than random. What this tells us is that the quality of what you put into the prompt has a direct, measurable effect on what comes back. The system does not magically compensate for sparse or poorly structured inputs. The content you give it, the specificity of the question, and the contextual grounding you provide all shape the result. For organizations with well-structured, componentized content, this is a significant advantage — one that is worth investing in before the AI project begins.
What We Learned That You Can Actually Use

A few things stood out as genuinely applicable across organizations of different sizes.
First: AI projects are more about content than technology. The pipes matter, but what flows through them matters more.
Second: define success before you start. Know what you are trying to achieve and what your tolerance for inaccurate outputs actually is — it varies by use case, and legal teams often have strong opinions.
Third: AI will not replace your writing team, but writers may need to adapt how they work.
Fourth: generative AI requires high-quality data, and most organizations do not have it yet. The question to ask honestly is whether your content is ready.
Fifth: we use AI in our own work, and we say this clearly — verify everything. Do not trust outputs without checking them against authoritative sources. That is not a caveat. It is the practice.
Next Steps and Where to Find More

Our next phase of the project focused on retrieval-augmented generation. The plan was to get access to the XML source behind the publications we used, chunk the content into intelligent content containers, build a semantically aware taxonomy around those objects, and connect them to a knowledge graph. When a question cane in, the system queried the knowledge graph first to identify relevant subject areas, retrieved the associated content components, and embed those into the prompt — a more structured and reliable approach than what we did in this first round.
We were unable to complete this work before LavaCon because we lost six weeks of access due to a bug in the Azure environment. But the direction was clear, and we reported what we found in our case study. A summary of this case study and a checklist of considerations for organizations participating in AI projects is available at ditastrategies.com/ai-case-study.
If your organization is heading into an AI project and you are trying to figure out where content quality, structure, and taxonomy fit into that work, that is a conversation worth having at the beginning.
Book a free discovery call with Amber Swope.