The Information Architect's Role in a Successful DITA Implementation

I presented this material at a Society for Technical Communication meeting in February 2024, to an audience of technical communicators at various stages of DITA adoption.

What Information Architecture Actually Is

Information architecture is the art and science of organizing information so that it is findable, manageable, and useful. I use that definition deliberately because the "art" part matters. Give the same challenge to five different information architects and 80% of what you get back will be the same — but that 20% variation reflects experience, judgment, and understanding of the landscape. That is what makes it an art and a science.
One way I describe the difference between a writer and an information architect: think of a photographer versus an x-ray technician. A photographer capturing a room sees the colors, the textures, the light. An x-ray of the same space shows none of that — it shows the structure beneath. Information architecture, at its core, is looking past the fonts and the stylesheets and asking: what is this content actually communicating, what is its purpose, and how do we identify that semantically so it can be optimized for any delivery context? If you create content and organize it in any way — a table of contents, a navigation structure — you are already performing the role of information architect. The question is how intentionally.
Management IA vs. Delivery IA: Why the Distinction Matters
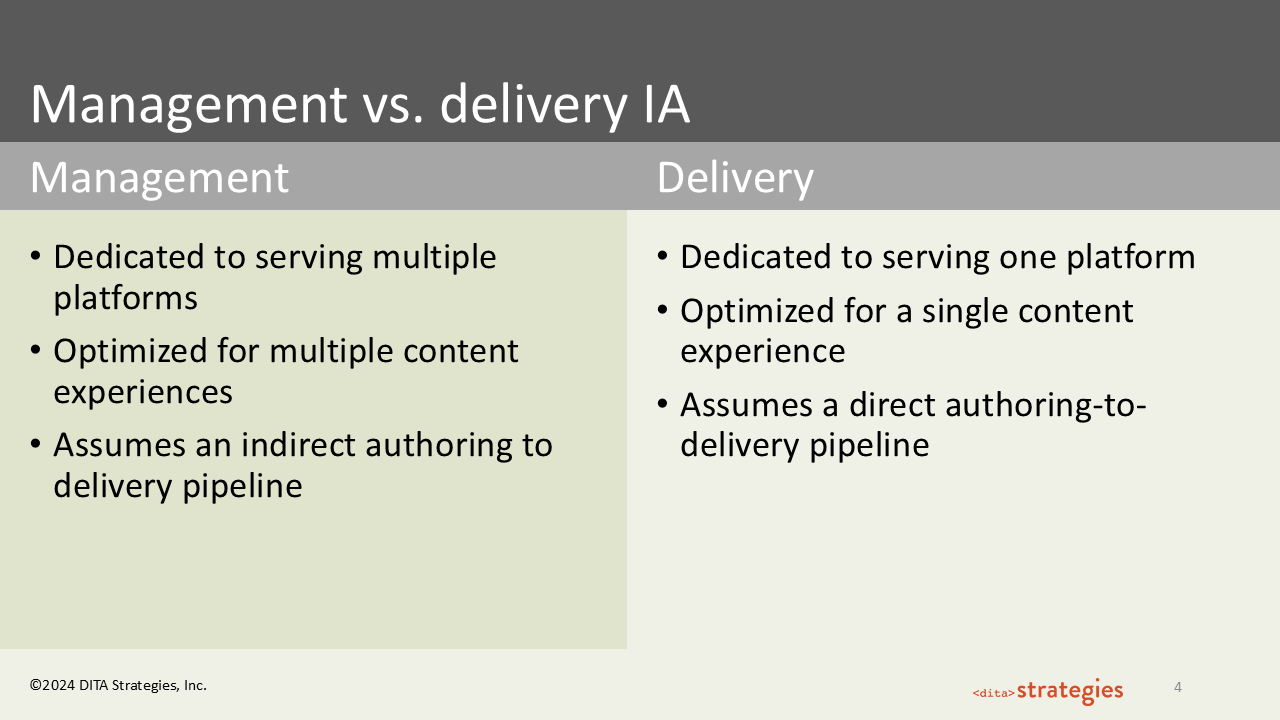
There are two distinct types of information architecture, and most of the field focuses on only one of them. If you search "information architecture," roughly 95% of what you find is about delivery IA — and that makes sense, because there are many more contexts in which people consume content than there are repositories where content has to be managed at the source. Delivery IA is focused on a single platform: SEO, navigation, user experience, frictionless access to information at point of consumption.
Management IA is different. It is focused on the source — the raw XML in a source control system like Git, or a component content management system. Management IA is meant to serve multiple delivery platforms simultaneously. The goal is what I call a harmonization exercise: you take the requirements of all your delivery platforms and harmonize them into a unified content model, with the goal of providing as much shared content as possible while acknowledging that each platform will have some unique requirements.
Confusing the two types of information architecture is one of the most consistent problems I see.
One Architecture Serving Many Platforms
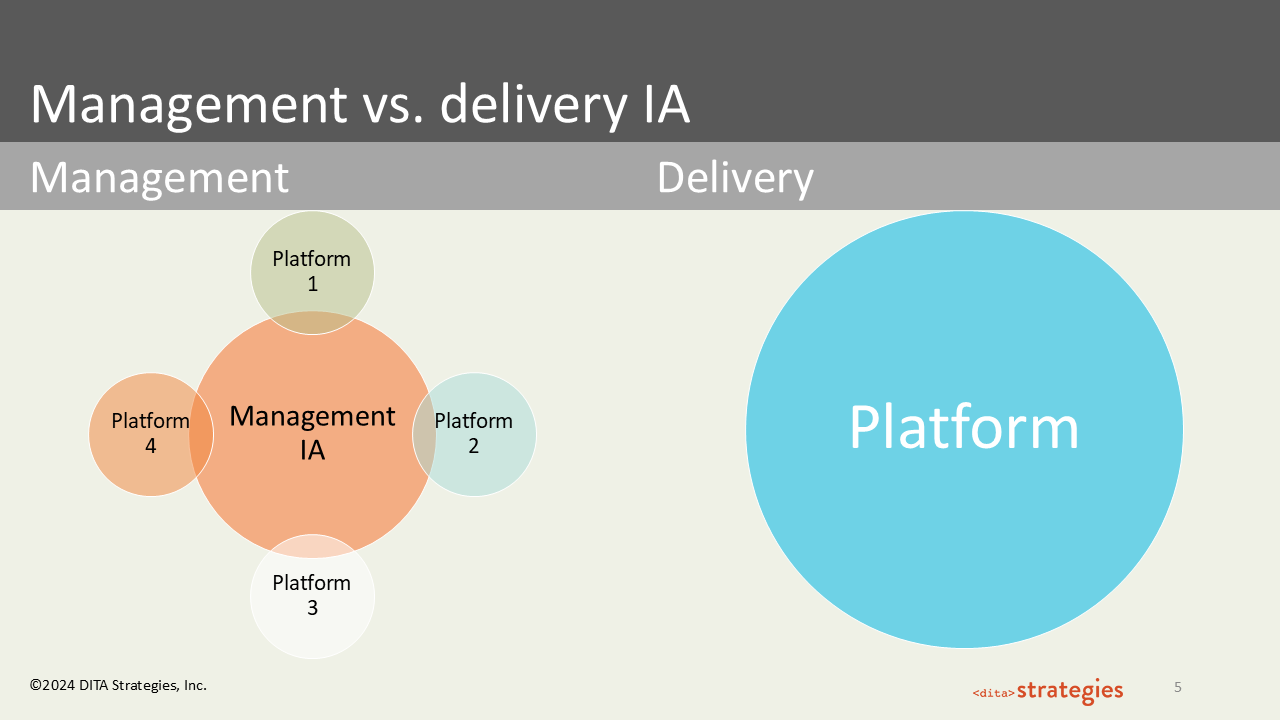
The best example I have for what management IA looks like in practice is a client that was a professional educational company. When I came in, it took them five months to produce their core print training book. Everything in that book was then manually copied and pasted out of InDesign and restructured for their LMS. The same content had to be reformatted for a mobile app delivering daily flashcard-style quizzes, and separately packaged for regulatory compliance submissions. Every channel required its own manual effort.
When we moved to DITA, we built a management IA — one central repository with a unified content model. From that single source, we could transform the content for InDesign, publish directly to the LMS as a SCORM package, extract glossary terms as a separate XML flavor for the mobile app, and generate a PDF for regulatory review. All from the same source.
The management IA sat at the center. Each delivery platform drew from it.
That is what the diagram on this slide is showing: not one platform served well, but all platforms served from one architecture. The delivery model on the right side of the slide — a single platform with no structural relationship to anything else — is what organizations build when they do not plan for management IA from the start.
The DITA Maturity Model: Investment and Return
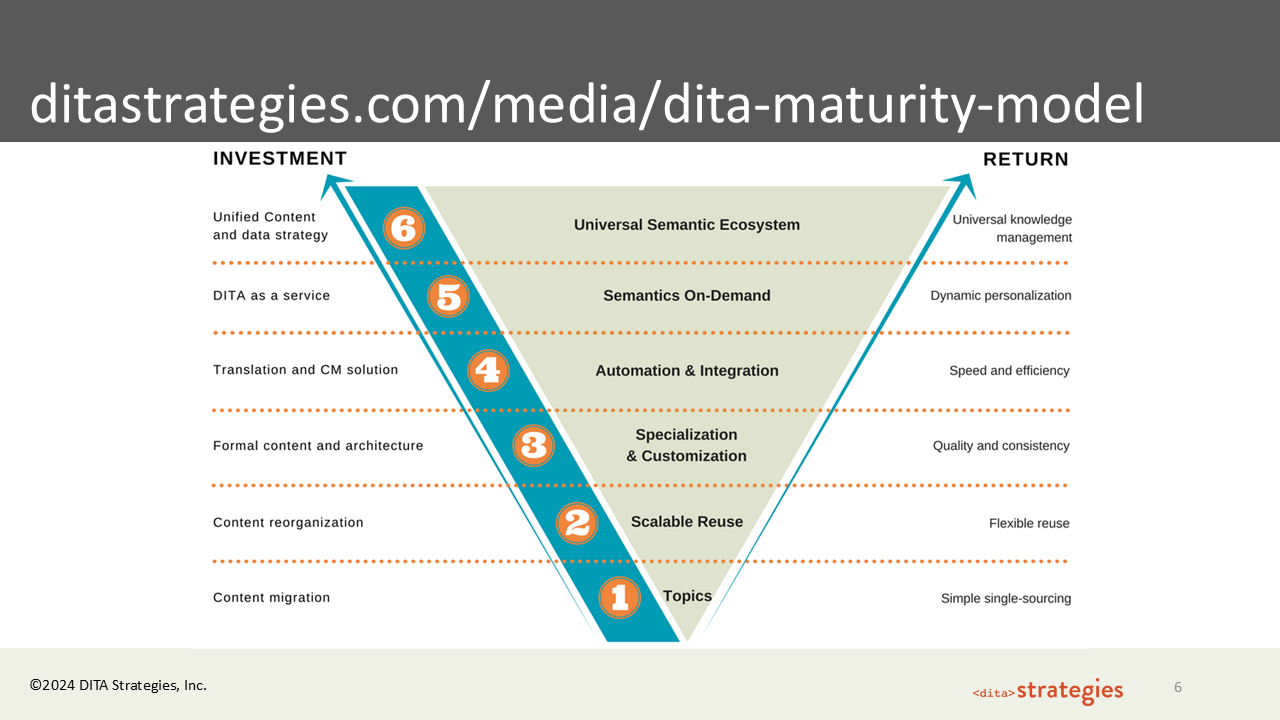
The DITA Maturity Model, which I co-authored with Michael Priestley in 2007, exists because organizations need a way to understand what they have to invest to get the returns they want. The model has six levels.
Level 1 is Topics: content migration, valid XML, simple single-sourcing. Valid does not mean useful — you can bring an entire book in as one big topic and it will pass validation. What you will not get is any of the flexibility that comes with more modular content.
Level 2 is Scalable Reuse, where the architecture starts to take shape. The base DITA topic types — concept, task, reference, and others — have separate structures because the purposes of those content types are genuinely different. If you want reuse, you have to break content apart by purpose first, then understand what structure each purpose requires.
Level 3 is Specialization and Customization, where you can extend the DITA standard to name elements your organization needs — a part number element, a policy type, an application guidance type. That additional granularity gives you cleaner associations, better reporting, and more specific author templates.
Level 4 moves into Automation and Integration, typically where a CCMS becomes necessary. A CCMS manages individual topics as discrete units with lifecycle tracking, bulk metadata application, and publishing integration — a qualitatively different capability than managing content in a source control system built for code.
Levels 5 and 6 move into semantics on demand and a universal semantic ecosystem. This is where taxonomy and metadata bind managed content to its delivery context, and where the payoff for structured content becomes most visible for AI. A semantically granular, consistently structured content set is in a fundamentally different position for AI than a bucket of words.
The full model is available at ditastrategies.com/media/dita-maturity-model.
One important note on how to use the DMM: it is sequential. You do not get scalable reuse without topics, and you do not reach semantic granularity without content broken into reusable units at the right level.
The Good News and the Bad News About DITA

The good news is that DITA is an architecture. The bad news is that DITA is an architecture.
DITA was designed as an open standard usable across any industry, so it deliberately includes flexible mechanisms — multiple reuse options, nearly 1000 elements — to accommodate that range. Most teams I work with use between 80 and 100 of those elements.
That flexibility is what makes DITA powerful and also what makes it require real architectural thinking to implement well. You cannot hand an organization a DITA toolchain and expect the tools to make the decisions. The decisions have to come first.
Organizations that treat DITA as a formatting upgrade rather than a content architecture they are committing to end up with technically valid XML that does not solve their actual content problems. A 100-page FrameMaker file migrated into one big topic is valid DITA. It is not reusable DITA. The architecture has to be thought through before authoring begins, and it does not stop there — the management information architect's work is present at every stage of the content lifecycle that follows.
What IA Decisions DITA Requires at Every Stage

Information architecture is not a front-end activity that ends when authoring begins. This slide maps the specific IA decisions that belong at each stage of the DITA content lifecycle, and the point is that the architect's work shows up throughout.
At the Convert and Author stage, the information architect defines the content model, topic structure, map structure, reuse strategy, metadata strategy, and validation rules. Validation rules deserve particular attention: they are the bumpers in the bowling alley gutters. They are what prevents authors from getting unexpected output at the end of a long day when they are trying to leave. If your DITA environment does not have them, that is worth addressing.
At the Manage stage, the focus shifts to metadata strategy and reuse strategy — the intelligence that determines what content goes where and how it gets there.
Localization requires both a content model and a metadata strategy. A concrete example: in English, we italicize the first instance of a term, a citation, and text for emphasis. If that italicized text goes to translation as formatting, the translator is guessing at meaning. If the first instance of a term is wrapped in a term element, the translator knows exactly what they are working with, and a stylesheet can render it correctly for any target language — including languages that do not use italics at all. That semantic clarity is the architect's job to build in.
Publishing requires a publication structure, metadata strategy, and validation rules.
Delivery requires a metadata strategy and a publication output structure.
The architect's job at every stage is making sure the right intelligence is embedded in the right content so it has a reliable path to where it needs to go.
If you are in the middle of a DITA implementation and finding that the content is technically valid but not behaving the way you need it to — not reusing cleanly, not publishing consistently across platforms, not positioned for the AI integrations your organization is asking about — that is usually an architecture problem, and it is a solvable one. Book a free discovery today to learn how we can help you.